

Our method enables semantic matching-based transfer even in challenging samples where the target object and the reference object belong to different categories or exhibit different styles.

Our method can individually transfer the appearance of multiple objects in the target image, each from a different reference image.
As pretrained text-to-image diffusion models have become a useful tool for image synthesis, people want to specify the results in various ways. In this paper, we introduce a method to produce results with the same structure of a target image but painted with colors from a reference image, especially following the semantic correspondence between the result and the reference. E.g., the result wing takes color from the reference wing, not the reference head. Existing methods rely on the query-key similarity within self-attention layer, usually producing defective results. To this end, we propose to find semantic correspondences and explicitly rearrange the features according to the semantic correspondences. Extensive experiments show the superiority of our method in various aspects: preserving the structure of the target and reflecting the color from the reference according to the semantic correspondences, even when the two images are not aligned.
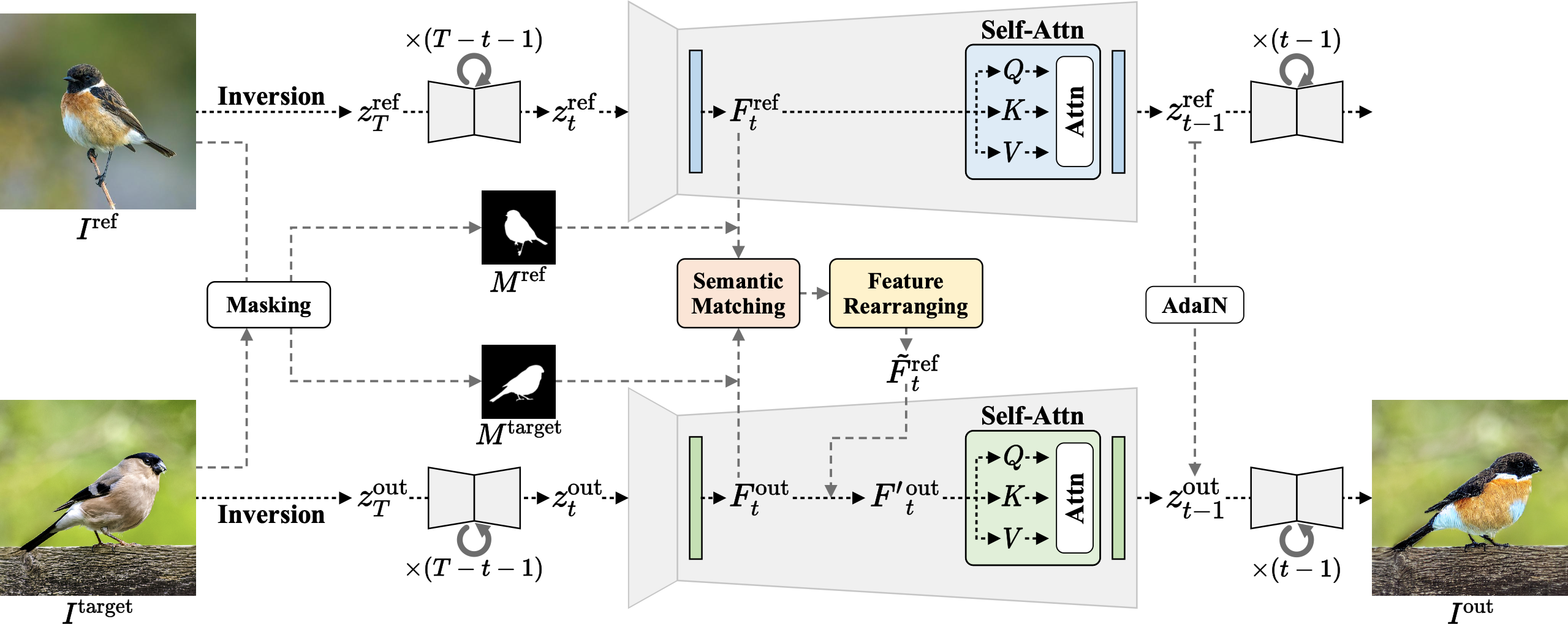
We transfer the semantically corresponding appearance of objects from a reference image to a target image. Given \( I^\text{ref} \), \( I^\text{target} \), and their masks \( M^\text{ref} \) and \( M^\text{target} \), we find semantic correspondences between their self-attention features \( F^\text{ref}_t \) and \( F^\text{out}_t \). Then, we inject the rearranged features based on these correspondences.

This is the attention maps for the target image's query pixel (red dot) during appearance transfer.
The \( KV \) injection(first row) and \( V \) injection(second row) perform semantic matching in the same manner as our method but apply the rearrangement and injection processes to \( KV \) and \( V \) instead of the feature map, respectively.
Our method rearranges the reference feature according to the semantic correspondence to the target and replace the target feature with it. Hence, our results have the visual elements of the reference arranged in the semantic structure of the target. In contrast, \( KV \) injection and \( V \) injection keeps the target query which leads to high attention from the orange-ish belly in the target to red parts in the reference as shown in the attention maps (yellow boxes of (c)).

@misc{go2024eyeforaneye,
author={Sooyeon Go and Kyungmook Choi and Minjung Shin and Youngjung Uh},
title={Eye-for-an-eye: Appearance Transfer with Semantic Correspondence in Diffusion Models},
year={2024},
eprint={2406.07008},
archivePrefix={arXiv},
primaryClass={cs.CV}
}